
Creating high-fidelity 3D meshes with arbitrary topology,
including open surfaces and complex interiors, remains a significant challenge.
Existing implicit field methods often require costly and detail-degrading watertight conversion,
while other approaches struggle with high resolutions. This paper introduces SparseFlex,
a novel sparse-structured isosurface representation that enables differentiable mesh
reconstruction at resolutions up to 10243 directly from rendering losses.
SparseFlex combines the accuracy of Flexicubes with a sparse voxel structure,
focusing computation on surface-adjacent regions and efficiently handling open surfaces.
Crucially, we introduce a frustum-aware sectional voxel training strategy that activates
only relevant voxels during rendering, dramatically reducing memory consumption and enabling
high-resolution training. This also allows, for the first time, the reconstruction of mesh
interiors using only rendering supervision. Building upon this, we demonstrate a complete
shape modeling pipeline by training a variational autoencoder (VAE) and a rectified
flow transformer for high-quality 3D shape generation. Our experiments show state-of-the-art
reconstruction accuracy, with a ~82% reduction in Chamfer Distance and a ~88% increase
in F-score compared to previous methods, and demonstrate the generation of high-resolution,
detailed 3D shapes with arbitrary topology. By enabling high-resolution, differentiable
mesh reconstruction and generation with rendering losses, SparseFlex significantly
advances the state-of-the-art in 3D shape representation and modeling.
Some 3D assets are from Zbalpha Collections, Objaverse, and Toys4K dataset.
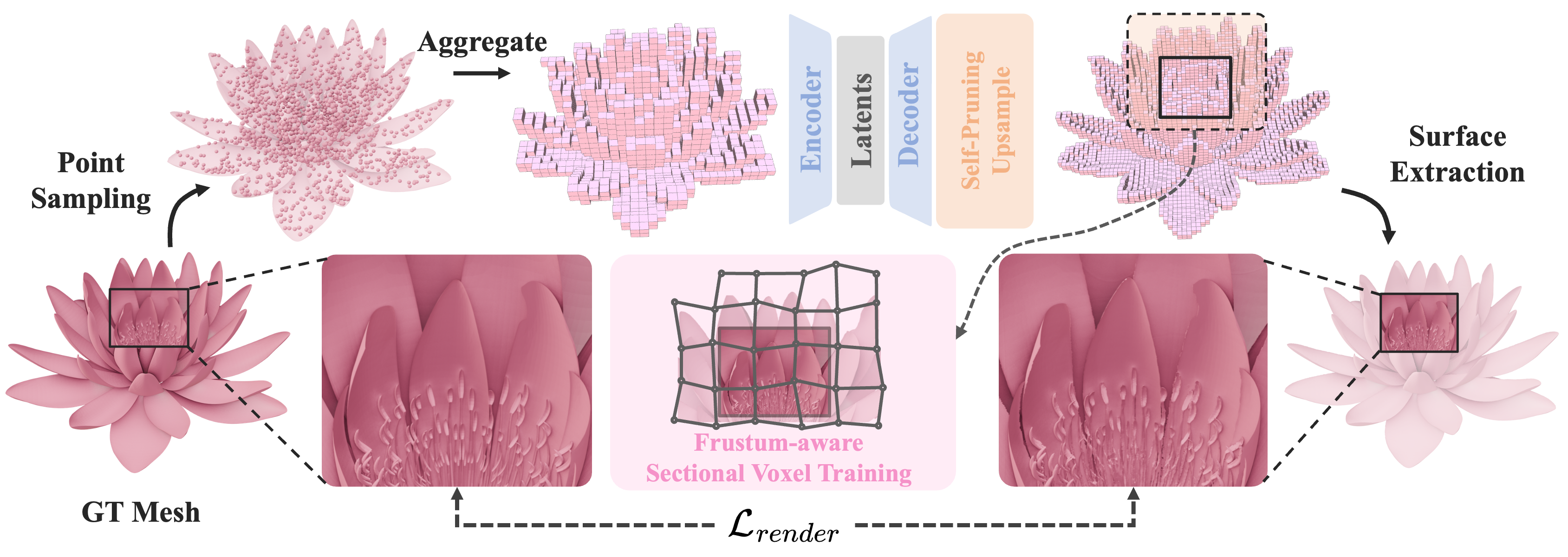
Our TripoSF VAE takes point clouds sampled from a mesh as input, voxelizes them, and aggregates their features into each voxel. A sparse transformer encoder-decoder compresses the structured feature into a more compact latent space, followed by a self-pruning upsampling for higher resolution. Finally, the structured features are decoded to SparseFlex representation through a linear layer. Using the frustum-aware section voxel training strategy, we can train the entire pipeline more efficiently by rendering loss.
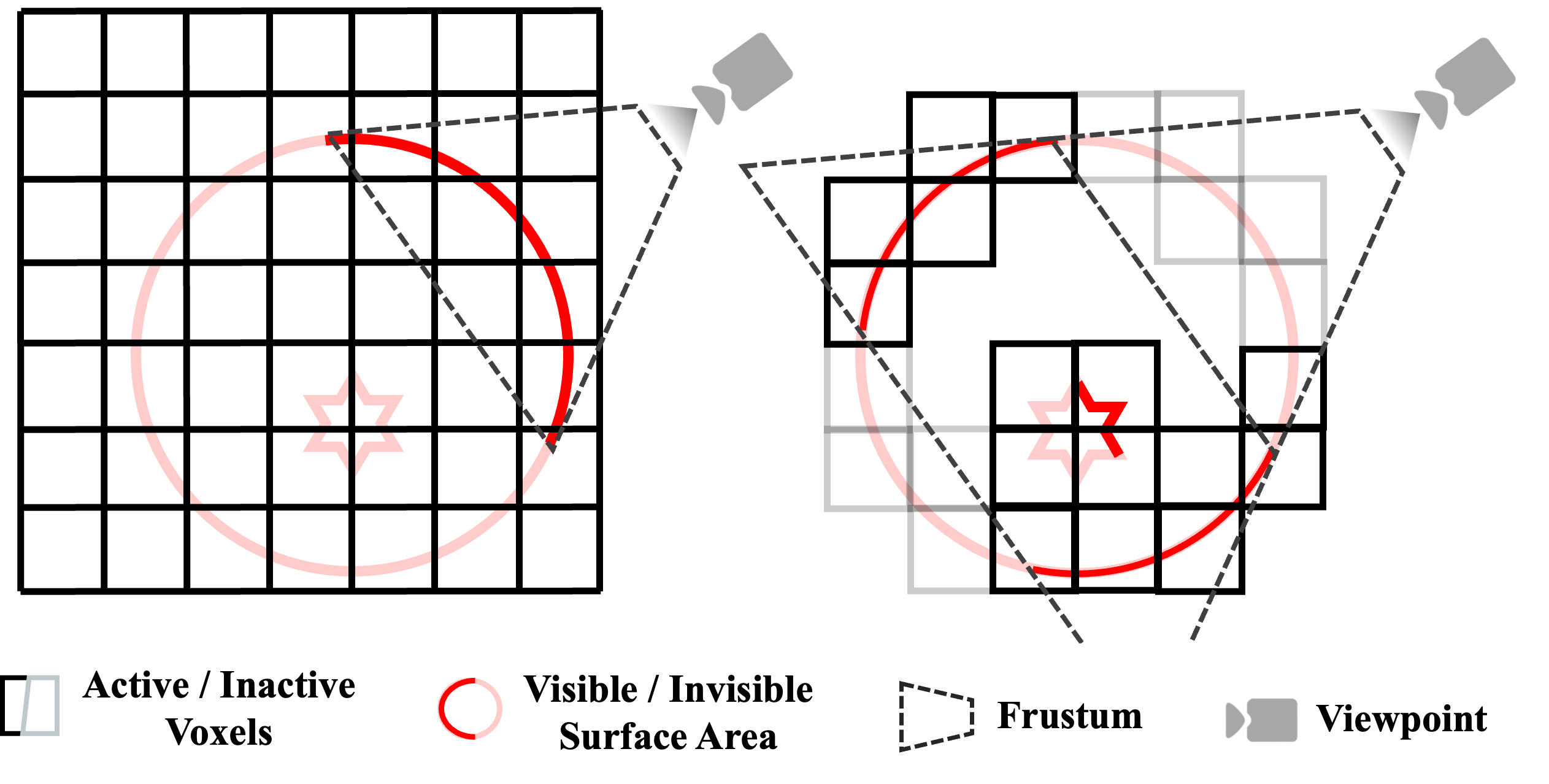
The previous mesh-based rendering training strategy (left) requires activating the entire dense grid to extract the mesh surface, even though only a few voxels are necessary during rendering. In contrast, our frustum-aware section voxel training strategy (right) adaptively activates the relevant voxels and enables the reconstruction of mesh interiors only using rendering supervision.







